Two recent articles have appeared in respected publications on Groupthink: first is an NYTimes op-ed piece by Susan Cain on January 15th, and second is an article by Jonah Lehrer in the January 30th issue of New Yorker. (see here for a scanned PDF of the full article if you are not a subscriber.) Both authors have upcoming books on group creativity[4,5]. I was intrigued enough to do further readings based on the works cited in these articles. This blog post summarizes and links to those works for anyone interested in digging deeper.
[As an aside, after reading the underlying papers and studies cited in these articles, I was actually disappointed with the liberal oversimplifications that appeared to have been made by these pop writers, routinely papering over the disclaimers and conditions mentioned in the original papers. But I will leave that for another blog post.]
Jonah Lehrer in the New Yorker
The traditional brainstorming mantra prescribes forgoing judgment and criticism during a brainstorming session so as to maximise the quantity of free-flowing ideas and to not get any distractions from judgment. The word “brainstorm” and this mantra was put forth by Alex Osborn in his 1948 book “Your Creative Power.” However, it never stood up to empirical observations! Keith Sawyer, a psychologist at Washington University, is cited by Lehrer as summarizing the findings thus: “Decades of research have consistently shown that brainstorming groups think of far fewer ideas than the same number of people who work alone and later pool their ideas.” Ouch!
Lehrer does not advocate solitary work though. The fact is that it takes teams to produce substantive works. He refers to a study by Prof. Ben Jones which observed that the impact (quantified by the number of citations) of multi-author papers and patents (and especially across Tier-1 universities) are much higher than those of single author ones.
How should then groups maximize creativity?
To develop the answer, Lehrer cites the studies of psychology Prof. Charlan Nemeth at Berkeley and sociologist Brian Uzzi at Northwestern.
Nemeth observes that the groups doing traditional brainstorming consistently underperformed those groups that were given the instruction to engage in debate during brainstorming. Lehrer quotes her: “Maybe debate is going to be less pleasant, but it will always be more productive.” Also “Authentic dissent can be difficult, but it’s always invigorating. It wakes us right up.” I personally observed the waking up part recently after receiving some unexpected but deserved criticism from a respected colleague.
Uzzi has studied for a long time the ideal composition of a team with respect to “Q” – a quantification by him of a team’s existing density of connections and mutual familiarity. Studying the composition of Broadway musical teams, he found that having worked together correlates positively with the success of the musical. But he also found rather surprisingly that a team being too familiar with each other was bad for its work! In other words, the best shows were produced by networks with an intermediate level of social intimacy. Lehrer says: “A team at the bliss point i.e., with the ideal level of Q between 2.4 and 2.6 was 3x more likely to be successful than one with Q lower than 1.4 or higher than 3.2.”
Centralized Bathrooms and Knowledge Spillovers
Lehrer then turns his attention to organization of physical space to maximize productivity. He cites a study by Isaac Kohane from Harvard Medical school on physical distance between collaborating biomedical researchers with in Harvard. Kohane observed that the most cited papers were consistently by collaborators working within ten metres of each other, while the least cited ones tended to emerge from collaborators who were a kilometre or more apart. [This study was not done on a global framework, so should not mislead us to think that across-university collaborations are less impactful. On the contrary, this study by Ben Jones indicates that across-university collaborations have been consistently on the rise and much more impactful than solo. Disappointingly, Lehrer omits the disclaimers in Kohane’s original paper as well as the across-university collaborative research.]
So there are two needs that need to be reconciled: (1) collaborators need to work physically closely together, and (2) collaborators need to get diverse perspectives and inject in themselves a moderate amount of novel perspectives. Lehrer talks about Steve Jobs’s deliberate attempts to create such an environment in Pixar that encouraged chance interactions of people from diverse teams with each other, causing various opportunities for “Knowledge Spillovers.” Finally, Lehrer talks about “Building 20” at MIT that was referred to as “the magical incubator”. Apparently, this building was under-designed and happened to be so “poorly structured” that scientists were forced to mingle. For example, the wings were oddly ordered, a large horizontal layout encouraged more chance interactions and individual scientists were free to reorganize their space as they needed. The lesson, Lehrer says, is that “the most creative spaces are those that hurl us together. It is the human friction that makes the sparks.”
Susan Cain in the New York Times
Susain Cain writes about “The Rise of the New Groupthink” in the January 13th op-ed. She first cites studies by psychologists Mihaly Csikszentmihalyi and Gregory Feist (and quotes many historical famous personalities) according to whom the most spectacularly creative people in many fields are often introverted, and that people produce more and better quality work when alone than in groups. Note that this is in direct contrast to what Keith Sawyer has said that innovation comes from collaboration in his book “Group Genius.” Interestingly, Lehrer cited Sawyer while debunking the traditional theory of brainstorming.
About office plans, she writes: “Studies show that open-plan offices make workers hostile, insecure and distracted. They’re also more likely to suffer from high blood pressure, stress, the flu and exhaustion. And people whose work is interrupted make 50 percent more mistakes and take twice as long to finish it.”
Similar to Lehrer, Cain writes that brainstorming doesn’t work, partly because people instinctively or unconsciously mimic each other. She even cites an Emory University neuroscientist Gregory Berns who found that when we take a stance different from the group’s, we activate the amygdala, a small organ in the brain associated with the fear of rejection.
However, according to Cain, electronic brainstorming works well – perhaps “because the screen protects us from too much groupthink.” This is surprising and counterintuitive to me.
Cain clarifies that she is not suggesting that teams should be abolished and everybody should be a loner, but that office spaces need to be designed such that people can have “casual, cafe like discussions but also be able to easily disappear into personal and private spaces”.
In my humble opinion, Cain might be mixing up individual and team’s productivity and creativity. Indeed, individuals are most productive when working in solitude, more so when we are talking about exceptional geniuses. However, many studies have shown by now that collaborative groups can do far more and better work than individuals working together in isolation. An organization is after all not the sum of each individual’s achievements, it is the sum of each team’s achievements. I guess Cain’s book [4] throws more light into her argument.
Further Reading
[1] Group creativity: music, theater and collaboration. R. Keith Sawyer (2003).
[2] Group Creativity: Innovation through Collaboration.Paul B. Paulus and Bernard A. Nijstad (2003).
[3] Managing innovation: when less is more. Charlan Nemeth (1997).
Nemeth cites previous studies about “visionary” companies that state that such companies develop a cult-like sense of belonging and similarity in thinking that grows more similar over time. While this promotes cohesion and shared goals, the environment needed for creativity is directly the opposite (unless the creativity comes directly from the CEO). Nemeth suggests organizations should not just be tolerant, but especially welcoming of minority views. Interestingly, minority views create value independent of whether they are right or wrong, perhaps simply by breaking conformity and discouraging complacency.
[4] Quiet: The Power of Introverts in a World That Can’t Stop Talking. Susan Cain (2012).
[5] Imagine: How Creativity Works. Jonah Lehrer (coming up in March 2012).


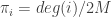 . This distribution is unique iff the graph is also aperiodic. An analogous result holds when the graph is weighted if we define
. This distribution is unique iff the graph is also aperiodic. An analogous result holds when the graph is weighted if we define  .
.
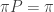 where
where  is the stochastic matrix defining the transition probability of going from state i to state j. Now, with a uniform random walk, each edge out of i can be taken with the same probability. i.e.,
is the stochastic matrix defining the transition probability of going from state i to state j. Now, with a uniform random walk, each edge out of i can be taken with the same probability. i.e.,  . So,
. So,

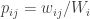 where
where  . Also, let
. Also, let 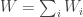 . The stationary vector is then defined by
. The stationary vector is then defined by 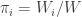 . The proof is very similar to the above.
. The proof is very similar to the above.